Recursion
Fork this
https://github.com/iloveponies/recursion
Here are the instructions if you need them. Be sure to fork the repository behind the link above.
Recap
This chapter talks a lot about collections and we’ll need the functions first and rest:
(doc first)
(doc rest)
(first [1 2 3 4]) ;=> 1
(first '(1 2 3 4)) ;=> 1
(rest [1 2 3 4]) ;=> (2 3 4)
(rest '(1 2 3 4)) ;=> (2 3 4)
(rest [1]) ;=> ()
(rest []) ;=> ()first gives the first element of a sequence, and rest gives all but the first element.
Recursion
So far we’ve manipulated collections with functions like map and filter. How do they work? They are all based on recursion. Recursion is the low-level method of iteration found in functional languages. While the higher-level functions like map are usually nicer to use than implementing the equivalent algorithm with recursion ourselves, there are often situations when the structure of the algorithm or the data it operates on is such that the existing higher-level functions do not quite work on it.
Lists are recursive structures
Let’s look at the function cons. It takes two parameters, a value and a sequence, and returns a new sequence with the value added to the front of the original sequence. For an example, to construct the sequence (1 2 3 4), we could write:
(cons 1
(cons 2
(cons 3
(cons 4 '()))))
;=> (1 2 3 4)'() is the empty sequence.
To process this nested structure suggests that we should first process the first element of the sequence, and then do the operation again on the rest of the sequence. This is actually the general structure of linear recursion. As a concrete example, let’s look at how to implement sum.
(defn sum [coll]
(if (empty? coll)
0
(+ (first coll)
(sum (rest coll)))))
(sum [1 2 3 4]) ;=> 10The sum of a sequence is:
- 0, if the sequence is empty, or
- the first element of the sequence added to the sum of the rest of the sequence.
Imagine an arrow drawn from the second sum to the first sum. This is the recursive nature of the algorithm.
The call to sum begins by inspecting coll. If coll is empty, sum immediately returns 0. If coll is not empty, sum takes its first element and adds it to the sum of the rest of the elements of coll. The value 0 is the base case of the algorithm, which determines when the calculation stops. If we did not have a base case, the calculation would continue infinitely.
Exercise 1
Write the function (product coll) that computes the product of a collection of values. The product of \(a\), \(b\) and \(c\) is \(a * b * c\).
(product []) ;=> 1 ; special case
(product [1 2 3]) ;=> 6
(product [1 2 3 4]) ;=> 24
(product [0 1 2]) ;=> 0
(product #{2 3 4}) ;=> 24 ; works for sets too!To get a better grasp on what sum does, let’s see how it’s evaluated.
(sum '(1 2 3 4))
= (sum (cons 1 (cons 2 (cons 3 (cons 4 '())))))
;=> (+ 1 (sum (cons 2 (cons 3 (cons 4 '())))))
;=> (+ 1 (+ 2 (sum (cons 3 (cons 4 '())))))
;=> (+ 1 (+ 2 (+ 3 (sum (cons 4 '())))))
;=> (+ 1 (+ 2 (+ 3 (+ 4 (sum '())))))
;=> (+ 1 (+ 2 (+ 3 (+ 4 0)))) ; (empty? '()) is true, so (sum '()) ;=> 0
;=> (+ 1 (+ 2 (+ 3 4)))
;=> (+ 1 (+ 2 7))
;=> (+ 1 9)
;=> 10Note that we expanded the list '(1 2 3 4) to its cons form. If we take a closer look at that form and the line with comment above, we’ll see why:
(cons 1 (cons 2 (cons 3 (cons 4 '()))))
...
;=> (+ 1 (+ 2 (+ 3 (+ 4 0 ))))We replaced the cons operation in the recursive structure with + and '() with 0. That is, we transformed the data structure into a calculation with the same form but different result.
Exercise 2
Write down the evaluation of(product [1 2 4]) like we did for sum above. This exercise does not give any points and you do not need to return it.
From this we get the general template for linear recursion over collections:
(defn eats-coll [coll]
(if (empty? coll)
...
(... (first coll) ... (eats-coll (rest coll)))))The first branch of the if is the base case and determines the value of eats-coll when given an empty collection. The second branch determines what operation to apply on the elements of the collection.
We call this kind of computation linear because the expression it constructs grows linearly with the size of input.
Exercise 3
Write the function (singleton? coll) which returns true if the collection has only one element in it and false otherwise. This is a very useful helper function in the remainder of this chapter.
Do not use count as it can be expensive on long sequences. This function is not recursive.
(singleton? [1]) ;=> true
(singleton? #{2}) ;=> true
(singleton? []) ;=> false
(singleton? [1 2 3]) ;=> falseExercise 4
Write (my-last a-seq) that computes the last element of a sequence.
(my-last []) ;=> nil
(my-last [1 2 3]) ;=> 3
(my-last [2 5]) ;=> 5Exercise 5
Write the function (max-element a-seq) that computes returns the maximum element in a-seq or nil if a-seq is empty?
You can use the function (max a b) that returns the greater of a and b.
(max-element [2 4 1 4]) ;=> 4
(max-element [2]) ;=> 2
(max-element []) ;=> nilExercise 6
Write the function (seq-max seq-1 seq-2) that returns the longer one of seq-1 and seq-2. This is a helper for the next exercise. You do not need to use recursion here. It is okay to use count.
(seq-max [1] [1 2]) ;=> [1 2]
(seq-max [1 2] [3 4]) ;=> [3 4]Exercise 7
Write the function (longest-sequence a-seq) that takes a sequence of sequences as a parameter and returns the longest one.
(longest-sequence [[1 2] [] [1 2 3]]) ;=> [1 2 3]
(longest-sequence [[1 2]]) ;=> [1 2]
(longest-sequence []) ;=> nilSaving the list
All the functions so far, sum, product and last-element, transformed the list into a single value. This it not always the case with linear recursion. Our old friend (map f a-seq) is a good example of this. Here is the definition for it:
(defn my-map [f a-seq]
(if (empty? a-seq)
a-seq
(cons (f (first a-seq))
(my-map f (rest a-seq)))))See how nicely it fits in the general template for linear recursion? Only deviation from it is the extra parameter f. It is function, that will become part of the operation that the recursion applies to the elements of the sequence. Here’s the evaluation:
(map inc [1 2 3])
;=> (cons (inc 1)
; (cons (inc 2)
; (cons (inc 3) '())))
;=> '(2 3 4)So map calls the function f for every element of a-seq and then re-constructs the sequence with cons.
Exercise 8
Implement the function (my-filter pred? a-seq) that works just like the standard filter. Don’t use remove.
(my-filter odd? [1 2 3 4]) ;=> (1 3)
(my-filter (fn [x] (> x 9000)) [12 49 90 9001]) ;=> (9001)
(my-filter even? [1 3 5 7]) ;=> ()Stopping before the end
Sometimes you can find the answer before hitting the base case. For example, the following function checks if a sequence contains only numbers. If we find something that isn’t a number on the way through, we can immediately stop and return false.
(defn only-numbers? [coll]
(cond
(empty? coll)
true ; the empty sequence contains only numbers
(number? (first coll))
(only-numbers? (rest coll)) ; we got a number, let's check the rest
:else
false)) ; it wasn't a number so we have our answerHere the recursion stops if we hit the base case (empty collection) or if we find a non-number.
(only-numbers? [1 2 3 4]) ;=> true
(only-numbers? [1 2 :D 3 4]) ;=> falseLet’s have a closer look at the evaluation of the second line:
(only-numbers? [1 2 :D 3 4])
;=> (only-numbers? [2 :D 3 4]) ; (number? 1) => true, so we now need to check
; if all the rest are numbers.
;=> (only-numbers? [:D 3 4]) ; because (number? 2) ;=> true
;=> false ; because (number? :D) ;=> falseExercise 9
Write the function (sequence-contains? elem a-seq) that returns true if the given sequence contains the given value, otherwise false.
(sequence-contains? 3 [1 2 3]) ;=> true
(sequence-contains? 3 [4 7 9]) ;=> false
(sequence-contains? :pony []) ;=> falseExercise 10
Write the function (my-take-while pred? a-seq) that returns the longest prefix of a-seq where pred? returns true for every element.
(my-take-while odd? [1 2 3 4]) ;=> (1)
(my-take-while odd? [1 3 4 5]) ;=> (1 3)
(my-take-while even? [1 3 4 5]) ;=> ()
(my-take-while odd? []) ;=> ()Exercise 11
Write the function (my-drop-while pred? a-seq) that drops elements from a-seq until pred? returns false.
(my-drop-while odd? [1 2 3 4]) ;=> (2 3 4)
(my-drop-while odd? [1 3 4 5]) ;=> (4 5)
(my-drop-while even? [1 3 4 5]) ;=> (1 3 4 5)
(my-drop-while odd? []) ;=> ()Recursing over many sequences
The template for linear recursion is very simple and is often too simple. For an example, consider the function (first-in val seq-1 seq-2), which returns 1 if the value val is found first in seq-1 and 2 if in seq-2. If val is not found in either sequence, first-in returns 0. val must not be nil.
(defn first-in [val seq-1 seq-2]
(cond
(and (empty? seq-1) (empty? seq-2)) 0
(= (first seq-1) val) 1
(= (first seq-2) val) 2
:else (first-in val (rest seq-1) (rest seq-2))))There’s an obvious reason why first-in doesn’t fit our template for linear recursion: it has three parameters, whereas the template only takes one. We can ignore the first parameter for our purposes, since it does not have bearing on the recursive structure of the computation. first-in is linearly recursive on both its sequence parameters, though.
Exercise 12
Write the function (seq= seq-1 seq-2) that compares two sequences for equality.
(seq= [1 2 4] '(1 2 4)) ;=> true
(seq= [1 2 3] [1 2 3 4]) ;=> false
(seq= [1 3 5] []) ;=> falseExercise 13
Write the function (my-map f seq-1 seq-2) that returns a sequence of the following kind . The first item is the return value of f called with the first values of seq-1 and seq-2. The second item is the return value of f called with the second values of seq-1 and seq-2 and so forth until seq-1 or seq-2 ends.
This is actually exactly how map works when given two sequences, but for the sake of practice don’t use map when defining my-map.
(my-map + [1 2 3] [4 4 4]) ;=> (5 6 7)
(my-map + [1 2 3 4] [0 0 0]) ;=> (1 2 3)
(my-map + [1 2 3] []) ;=> ()This behaviour of map with multiple sequence arguments can come in handy at times. One useful function to use with it is vector.
vector makes a vector of its arguments.
(vector 1 2) ;=> [1 2]
(vector 1 2 3 4) ;=> [1 2 3 4]With map, you can use this to turn two sequences into a sequence of pairs:
(map vector [1 2 3] [:a :b :c]) ;=> ([1 :a] [2 :b] [3 :c])
(map vector [1 2 3 4] [2 3 4]) ;=> [1 2] [2 3] [3 4]You can use this to get an indexed version of a sequence:
(defn indexed [a-seq]
(let [indexes (range 0 (count a-seq))]
(map vector indexes a-seq)))
(indexed [:a :b :c]) ;=> ([0 :a] [1 :b] [2 :c])Sometimes you need all consecutive pairs from a sequence. This, too, can be achieved with map and vector:
(defn consecutives [a-seq]
(map vector a-seq (rest a-seq)))
(consecutives [:a :b :c]) ;=> ([:a :b] [:b :c])
(consecutives [1 2 3 4]) ;=> ([1 2] [2 3] [3 4])Recursion on numbers
Another common data structure to recurse over are numbers. (Even though you might not think of numbers as data structures!) Recursing over numbers is very similar to recursing over sequences. As an example, let’s define a function to calculate the factorial of a number. (Factorial of \(n\) is \(1 \cdot 2 \cdots (n-1) \cdot n\).)
(defn factorial [n]
(if (zero? n)
1
(* n (factorial (dec n)))))The factorial function looks a lot like sum. Given the number n, We have the base case (return 1 if n is zero) and the recursive branch, which multiplies n with the factorial of (dec n), that is, (- n 1). To verify that this function really does implement the definition of factorial properly, we can look at how it is evaluated:
(factorial 4)
;=> (* 4 (factorial 3))
;=> (* 4 (* 3 (factorial 2)))
;=> (* 4 (* 3 (* 2 (factorial 1))))
;=> (* 4 (* 3 (* 2 (* 1 (factorial 0)))))
;=> (* 4 (* 3 (* 2 (* 1 1)))) ; Base case reached
;=> (* 4 (* 3 (* 2 1)))
;=> (* 4 (* 3 2))
;=> (* 4 6)
;=> 24The line where the base case is reached shows that the function does evaluate to the mathematical expression we wanted.
Let’s look a bit closer at how sequences and numbers are related. Where a sequence is constructed, numbers are incremented, and where a sequence is destructured with rest, a number is decremented with dec:
(inc (inc (inc 0))) ;=> 3
(cons 1 (cons 2 (cons 3 nil))) ;=> (1 2 3)
(dec (dec (dec 3))) ;=> 0
(rest (rest (rest [1 2 3]))) ;=> ()Sequences store more information than numbers – the elements – but otherwise the expressions above are very similar. (The numbers actually encode the length of the sequence. Conversely, sequences can be used to encode numbers. Benjamin Pierce’s Software Foundations is recommended reading if you’re interested in more off-topic esoterica.) With this relationship, we can make the evaluation of (factorial 4) even more similar to our example of sum:
(factorial (inc (inc (inc (inc 0))))) ; Unwrap inc with dec
;=> (* 4 (factorial (inc (inc (inc 0))))) ; like cons with rest
;=> (* 4 (* 3 (factorial (inc (inc 0))))) ; almost a haiku
;=> (* 4 (* 3 (* 2 (factorial (inc 0)))))
;=> (* 4 (* 3 (* 2 (* 1 (factorial 0)))))
;=> (* 4 (* 3 (* 2 (* 1 1)))) ; Base case reached
;=> (* 4 (* 3 (* 2 1)))
;=> (* 4 (* 3 2))
;=> (* 4 6)
;=> 24Let’s define the general template for recursion over (natural) numbers, like we did for sequences.
(defn eats-numbers [n]
(if (zero? n)
...
(... n ... (eats-numbers (dec n)))))Exercise 14
Write the function (power n k) that computes the mathematical expression \(n^k\).
(power 2 2) ;=> 4
(power 5 3) ;=> 125
(power 7 0) ;=> 1
(power 0 10) ;=> 0Nonlinear recursion
There are other recursive computations besides linear recursion. Another common type is tree recursion. Here tree refers again to the shape of the computation. The natural use for tree recursion is with hierarchical data structures, which we will come back to later. Tree recursion can be illustrated with simple processes over numbers. For an example, let’s look at how to compute the following integer series:
Let \(f(n) = \begin{cases} n & \text{ if } n < 3 \\ f(n - 1) + 2 \cdot f(n - 2) + 3 \cdot f(n - 3) & \text{ otherwise} \end{cases}\)
Translating this to Clojure gives us the following program:
(defn f [n]
(if (< n 3)
n
(+ (f (- n 1))
(* 2 (f (- n 2)))
(* 3 (f (- n 3))))))(The odd alignment is for clarity.) Consider how this function evaluates:
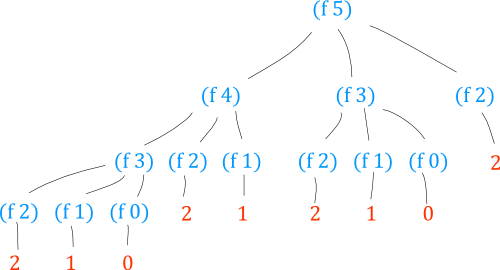
It is easy to see that the computation forms a tree structure.
Exercise 15
Compute the \(n\)th Fibonacci number. The \(n\)th Fibonacci number, \(F_n\), is defined as:
- \(F_0 = 0\)
- \(F_1 = 1\)
- \(F_n = F_{n-1} + F_{n-2}\)
Write the function (fib n) which returns \(F_n\).
(fib 0) ;=> 0
(fib 1) ;=> 1
(fib 2) ;=> 1
(fib 3) ;=> 2
(fib 4) ;=> 3
(fib 5) ;=> 5
(fib 6) ;=> 8
...
(fib 10) ;=> 55Sequence operations
We have already implemented some of the sequence functions found from the Clojure’s standard library, namely map and filter. In the following exercises you should use recursion to implement some more.
Exercise 16
Write the function (my-repeat how-many-times what-to-repeat) that generates a list with what-to-repeat repeated how-many-times number of times.
(my-repeat 2 :a) ;=> (:a :a)
(my-repeat 3 "lol") ;=> ("lol" "lol" "lol")
(my-repeat -1 :a) ;=> ()Exercise 17
Write the function (my-range up-to) that works like this:
(my-range 0) ;=> ()
(my-range 1) ;=> (0)
(my-range 2) ;=> (1 0)
(my-range 3) ;=> (2 1 0)Exercise 18
Write the functions tails and inits that return all the suffixes and prefixes of a sequence, respectively.
(tails [1 2 3 4]) ;=> ((1 2 3 4) (2 3 4) (3 4) (4) ())
(inits [1 2 3 4]) ;=> (() (1) (1 2) (1 2 3) (1 2 3 4))
; You can output the tails and inits in any order you like.
(inits [1 2 3 4]) ;=> ((1 2) () (1 2 3) (1) (1 2 3 4))Hint: You can use reverse and map.
(reverse [1 2 3]) ;=> (3 2 1)
(reverse [2 3 1]) ;=> (1 3 2)Exercise 19
Write the function (rotations a-seq) that, when given a sequence, returns all the rotations of that sequence.
(rotations []) ;=> (())
(rotations [1 2 3]) ;=> ((1 2 3) (2 3 1) (3 1 2))
(rotations [:a :b]) ;=> ((:a :b) (:b :a))
; The order of rotations does not matter.
(rotations [:a :b]) ;=> ((:b :a) (:a :b))
(rotations [1 5 9 2]) ;=> ((1 5 9 2) (2 1 5 9) (9 2 1 5) (5 9 2 1))
(count (rotations [6 5 8 9 2])) ;=> 5Keep in mind the function concat.
(concat [1 2 3] [:a :b :c]) ;=> (1 2 3 :a :b :c)
(concat [1 2] [3 4 5 6]) ;=> (1 2 3 4 5 6)Passing state
Sometimes when recursing over a structure we want to keep track of something. For an example, we might want to count how many elements we have processed, or how many :D keywords we have seen. How do we do this, in the absence of state in our language? (Or at least in the absence of instructions on how to use state on these pages!)
The answer is two-fold: we store the state explicitly in a parameter we pass back to ourselves on each recursion, and we hide the state from the users of our function by using a helper function that we give an initial empty state to as a parameter.
Here’s an example of a function that counts how many times a sequence contains a given element:
(defn count-elem-helper [n elem coll]
(if (empty? coll)
n
(let [new-count (if (= elem (first coll))
(inc n)
n)]
(count-elem-helper new-count
elem
(rest coll)))))
(defn count-elem [elem coll]
(count-elem-helper 0 elem coll))First, we define a helper function, count-elem-helper. It takes three parameters:
n, which keeps count of how many times we have seenelemelem, which is the element we are looking forand
coll, which is the collection the function recurses over.
With this helper function, our definition of count-elem is a simple call to count-elem-helper with n initialized to 0. This way users of count-elem do not need to provide the initialization argument for n.
Exercise 20
Write the function (my-frequencies a-seq) that computes a map of how many times each element occurs in a sequence. E.g.:
(my-frequencies []) ;=> {}
(my-frequencies [:a "moi" :a "moi" "moi" :a 1]) ;=> {:a 3, "moi" 3, 1 1}You’ll want to structure your code like this:
(defn my-frequencies-helper [freqs a-seq]
...)
(defn my-frequencies [a-seq]
(frequencies-helper {} a-seq))my-frequencies-helper is a recursive helper function.
Exercise 21
Write the function (un-frequencies a-map) which takes a map produced by my-frequencies and generates a sequence with the corresponding numbers of different elements.
(un-frequencies {:a 3 :b 2 "^_^" 1}) ;=> (:a :a :a "^_^" :b :b)
(un-frequencies (my-frequencies [:a :b :c :a])) ;=> (:a :a :b :c)
(my-frequencies (un-frequencies {:a 100 :b 10})) ;=> {:a 100 :b 10}The order of elements in the output sequence doesn’t matter.
Hint 1: Remember that you can use first and rest on a map too!
(first {:a 1 :b 2}) ;=> [:a 1]
(rest {:a 1 :b 2 :c 3}) ;=> ([:b 2] [:c 3])concat and repeat.
Merging and sorting
As a grande finale, let’s implement the classic merge sort. We have split the task into smaller exercises.
Exercise 22
Implement (my-take n coll) that returns n first items of coll.
(my-take 2 [1 2 3 4]) ;=> (1 2)
(my-take 4 [:a :b]) ;=> (:a :b)Exercise 23
Implement (my-drop n coll) that returns all but the n first items of coll.
(my-drop 2 [1 2 3 4]) ;=> (3 4)
(my-drop 4 [:a :b]) ;=> ()Exercise 24
Implement the function (halve a-seq) that takes a sequence and returns one vector with two elements. The first element is the first half of a-seq and the second element is the second half of a-seq.
To turn a result of division into an integer use int.
(int (/ 7 2)) ;=> 3(halve [1 2 3 4]) ;=> [(1 2) (3 4)]
(halve [1 2 3 4 5]) ;=> [(1 2) (3 4 5)]
(halve [1]) ;=> [() (1)]Exercise 25
Write the function (seq-merge a-seq b-seq) that takes two (low to high) sorted number sequences and combines them into one sorted sequence. Don’t use sort (nor implement it yourself, yet).
(seq-merge [4] [1 2 6 7]) ;=> (1 2 4 6 7)
(seq-merge [1 5 7 9] [2 2 8 10]) ;=> (1 2 2 5 7 8 9 10)Exercise 26
Write the function (merge-sort a-seq) that implements merge sort.
The idea of merge sort is to divide the input into subsequences using halve, sort the subsequences recursively and use the seq-merge function to merge the sorted subsequences back together.
Conceptually:
- If the sequence is 0 or 1 elements long, it is already sorted.
- Otherwise, divide the sequence into two subsequences.
- Sort each subsequence recursively.
- Merge the two subsequences back into one sorted sequence.
(merge-sort [4 2 3 1])
;=> (seq-merge (merge-sort (4 2))
; (merge-sort (3 1)))
;=> (seq-merge (seq-merge (merge-sort (4))
; (merge-sort (2)))
; (seq-merge (merge-sort (3))
; (merge-sort (1))))
;=> (seq-merge (seq-merge (4) (2))
; (seq-merge (3) (1)))
;=> (seq-merge (2 4) (1 3))
;=> (1 2 3 4)(merge-sort []) ;=> ()
(merge-sort [1 2 3]) ;=> (1 2 3)
(merge-sort [5 3 4 17 2 100 1]) ;=> (1 2 3 4 5 17 100)Encore
The following exercises are ment to be tricky. So don’t dwell too long on them. Move along and come back later.
These exercises will give extra points.
Exercise 27
2 points
Write the function split-into-monotonics that takes a sequence and returns the sequence split into monotonic pieces. Examples:
(split-into-monotonics [0 1 2 1 0]) ;=> ((0 1 2) (1 0))
(split-into-monotonics [0 5 4 7 1 3]) ;=> ((0 5) (4 7) (1 3))Hint: You might find useful the functions take-while, drop and inits. Make sure that your inits returns the prefixes from the shortest to the longest.
(inits [1 2 3 4]) ;=> (() (1) (1 2) (1 2 3) (1 2 3 4))Exercise 28
3 points
Given a sequence, return all permutations of that sequence.
(permutations #{})
;=> (())
(permutations #{1 5 3})
;=> ((1 5 3) (5 1 3) (5 3 1) (1 3 5) (3 1 5) (3 5 1))Exercise 29
3 points
Given a set, return the powerset of that set.
(powerset #{}) ;=> #{#{}}
(powerset #{1 2 4}) ;=> #{#{} #{4} #{2} #{2 4} #{1} #{1 4} #{1 2} #{1 2 4}}